P versus NP problem
| Is P = NP ? |
The P versus NP problem is a major unsolved problem in computer science. Informally, it asks whether every problem whose solution can be efficiently checked by a computer can also be efficiently solved by a computer. It was introduced in 1971 by Stephen Cook in his seminal paper "The complexity of theorem proving procedures"[2] and is considered by many to be the most important open problem in the field.[3] It is one of the seven Millennium Prize Problems selected by the Clay Mathematics Institute to carry a US$ 1,000,000 prize for the first correct solution.
In essence, the P = NP problem can be restated as the following question:
Suppose that solutions to a problem can be verified quickly. Then, can the solutions themselves also be computed quickly?
The theoretical notion of quickly used here is an algorithm that runs in polynomial time. The general class of questions for which some algorithm can provide an answer in polynomial time is called "class P" or just "P". For some questions, there is no known way to find an answer quickly, but if one is provided with information showing what the answer is, it may be possible to verify the answer quickly. The class of questions for which an answer can be verified in polynomial time is called NP.
Consider the subset sum problem, an example of a problem that is easy to verify, but whose answer may be difficult to compute. Given a set of integers, does some nonempty subset of them sum to 0? For instance, does a subset of the set {−2, −3, 15, 14, 7, −10} add up to 0? The answer "yes, because {−2, −3, −10, 15} add up to zero" can be quickly verified with three additions. However, there is no known algorithm to find such a subset in polynomial time (there is one, however, in exponential time, which consists of 2n-1 tries), and indeed such an algorithm cannot exist if the two complexity classes are not the same; hence this problem is in NP (quickly checkable) but not necessarily in P (quickly solvable).
An answer to the P = NP question would determine whether problems like the subset-sum problem that can be verified in polynomial time can also be solved in polynomial time. If it turned out that P does not equal NP, it would mean that there are problems in NP (such as NP-complete problems) that are harder to compute than to verify: they could not be solved in polynomial time, but the answer could be verified in polynomial time.
Context
The relation between the complexity classes P and NP is studied in computational complexity theory, the part of the theory of computation dealing with the resources required during computation to solve a given problem. The most common resources are time (how many steps it takes to solve a problem) and space (how much memory it takes to solve a problem).
In such analysis, a model of the computer for which time must be analyzed is required. Typically such models assume that the computer is deterministic (given the computer's present state and any inputs, there is only one possible action that the computer might take) and sequential (it performs actions one after the other).
In this theory, the class P consists of all those decision problems (defined below) that can be solved on a deterministic sequential machine in an amount of time that is polynomial in the size of the input; the class NP consists of all those decision problems whose positive solutions can be verified in polynomial time given the right information, or equivalently, whose solution can be found in polynomial time on a non-deterministic machine.[4] Clearly, P ⊆ NP. Arguably the biggest open question in theoretical computer science concerns the relationship between those two classes:
- Is P equal to NP?
In a 2002 poll of 100 researchers, 61 believed the answer to be no, 9 believed the answer is yes, and 22 were unsure; 8 believed the question may be independent of the currently accepted axioms and so impossible to prove or disprove.[5]
NP-complete
To attack the P = NP question the concept of NP-completeness is very useful. NP-complete problems are a set of problems to which any other NP-problem can be reduced in polynomial time, and whose solution may still be verified in polynomial time. Informally, an NP-complete problem is at least as "tough" as any other problem in NP. NP-hard problems are those at least as hard as NP-complete problems, i.e., all NP-problems can be reduced (in polynomial time) to them. NP-hard problems need not be in NP, i.e., they need not have solutions verifiable in polynomial time.
For instance, the decision problem version of the travelling salesman problem is NP-complete, so any instance of any problem in NP can be transformed mechanically into an instance of the traveling salesman problem, in polynomial time. The traveling salesman problem is one of many such NP-complete problems. If any NP-complete problem is in P, then it would follow that P = NP. Unfortunately, many important problems have been shown to be NP-complete, and as of 2012 not a single fast algorithm for any of them is known.
Based on the definition alone it is not obvious that NP-complete problems exist. A trivial and contrived NP-complete problem can be formulated as: given a description of a Turing machine M guaranteed to halt in polynomial time, does there exist a polynomial-size input that M will accept?[6] It is in NP because (given an input) it is simple to check whether M accepts the input by simulating M; it is NP-complete because the verifier for any particular instance of a problem in NP can be encoded as a polynomial-time machine M that takes the solution to be verified as input. Then the question of whether the instance is a yes or no instance is determined by whether a valid input exists.
The first natural problem proven to be NP-complete was the Boolean satisfiability problem. This result came to be known as Cook–Levin theorem; its proof that satisfiability is NP-complete contains technical details about Turing machines as they relate to the definition of NP. However, after this problem was proved to be NP-complete, proof by reduction provided a simpler way to show that many other problems are in this class. Thus, a vast class of seemingly unrelated problems are all reducible to one another, and are in a sense "the same problem".
Harder problems
Although it is unknown whether P = NP, problems outside of P are known. A number of succinct problems (problems that operate not on normal input, but on a computational description of the input) are known to be EXPTIME-complete. Because it can be shown that P 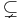 EXPTIME, these problems are outside P, and so require more than polynomial time. In fact, by the time hierarchy theorem, they cannot be solved in significantly less than exponential time. Examples include finding a perfect strategy for chess (on an N×N board)[7] and some other board games.[8]
EXPTIME, these problems are outside P, and so require more than polynomial time. In fact, by the time hierarchy theorem, they cannot be solved in significantly less than exponential time. Examples include finding a perfect strategy for chess (on an N×N board)[7] and some other board games.[8]
The problem of deciding the truth of a statement in Presburger arithmetic requires even more time. Fischer and Rabin proved in 1974 that every algorithm that decides the truth of Presburger statements has a runtime of at least 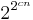 for some constant c. Here, n is the length of the Presburger statement. Hence, the problem is known to need more than exponential run time. Even more difficult are the undecidable problems, such as the halting problem. They cannot be completely solved by any algorithm, in the sense that for any particular algorithm there is at least one input for which that algorithm will not produce the right answer; it will either produce the wrong answer, finish without giving a conclusive answer, or otherwise run forever without producing any answer at all.
for some constant c. Here, n is the length of the Presburger statement. Hence, the problem is known to need more than exponential run time. Even more difficult are the undecidable problems, such as the halting problem. They cannot be completely solved by any algorithm, in the sense that for any particular algorithm there is at least one input for which that algorithm will not produce the right answer; it will either produce the wrong answer, finish without giving a conclusive answer, or otherwise run forever without producing any answer at all.
Problems in NP not known to be in P or NP-complete
It was shown by Ladner that if P ≠ NP then there exist problems in NP that are neither in P nor NP-complete.[1] Such problems are called NP-intermediate problems. The graph isomorphism problem, the discrete logarithm problem and the integer factorization problem are examples of problems believed to be NP-intermediate. They are some of the very few NP problems not known to be in P or to be NP-complete.
The graph isomorphism problem is the computational problem of determining whether two finite graphs are isomorphic. An important unsolved problem in complexity theory is whether the graph isomorphism problem is in P, NP-complete, or NP-intermediate. The answer is not known, but it is believed that the problem is at least not NP-complete.[9] If graph isomorphism is NP-complete, the polynomial time hierarchy collapses to its second level.[10] Since it is widely believed that the polynomial hierarchy does not collapse to any finite level, it is believed that graph isomorphism is not NP-complete. The best algorithm for this problem, due to Laszlo Babai and Eugene Luks has run time 2O(√(n log n)) for graphs with n vertices.
The integer factorization problem is the computational problem of determining the prime factorization of a given integer. Phrased as a decision problem, it is the problem of deciding whether the input has a factor less than k. No efficient integer factorization algorithm is known, and this fact forms the basis of several modern cryptographic systems, such as the RSA algorithm. The integer factorization problem is in NP and in co-NP (and even in UP and co-UP[11]). If the problem is NP-complete, the polynomial time hierarchy will collapse to its first level (i.e., NP = co-NP). The best known algorithm for integer factorization is the general number field sieve, which takes expected time O(e(64/9)1/3(n.log 2)1/3(log (n.log 2))2/3) to factor an n-bit integer. However, the best known quantum algorithm for this problem, Shor's algorithm, does run in polynomial time. Unfortunately, this fact doesn't say much about where the problem lies with respect to non-quantum complexity classes.
Does P mean "easy"?
All of the above discussion has assumed that P means "easy" and "not in P" means "hard", an assumption known as Cobham's thesis. It is a common and reasonably accurate assumption in complexity theory, however it has some caveats.
First, it is not always true in practice. A theoretical polynomial algorithm may have extremely large constant factors or exponents thus rendering it impractical. On the other hand, even if a problem is shown to be NP-complete, and even if P ≠ NP, there may still be effective approaches to tackling the problem in practice. There are algorithms for many NP-complete problems, such as the knapsack problem, the traveling salesman problem and the boolean satisfiability problem, that can solve to optimality many real-world instances in reasonable time. The empirical average-case complexity (time vs. problem size) of such algorithms can be surprisingly low. A famous example is the simplex algorithm in linear programming, which works surprisingly well in practice; despite having exponential worst-case time complexity it runs on par with the best known polynomial-time algorithms. [13]
Second, there are types of computations which do not conform to the Turing machine model on which P and NP are defined, such as quantum computation and randomized algorithms.
Reasons to believe P ≠ NP
According to a poll,[5] many computer scientists believe that P ≠ NP. A key reason for this belief is that after decades of studying these problems no one has been able to find a polynomial-time algorithm for any of more than 3000 important known NP-complete problems (see List of NP-complete problems). These algorithms were sought long before the concept of NP-completeness was even defined (Karp's 21 NP-complete problems, among the first found, were all well-known existing problems at the time they were shown to be NP-complete). Furthermore, the result P = NP would imply many other startling results that are currently believed to be false, such as NP = co-NP and P = PH.
It is also intuitively argued that the existence of problems that are hard to solve but for which the solutions are easy to verify matches real-world experience.[14]
If P = NP, then the world would be a profoundly different place than we usually assume it to be. There would be no special value in "creative leaps," no fundamental gap between solving a problem and recognizing the solution once it's found. Everyone who could appreciate a symphony would be Mozart; everyone who could follow a step-by-step argument would be Gauss...
On the other hand, some researchers believe that there is overconfidence in believing P ≠ NP and that researchers should explore proofs of P = NP as well. For example, in 2002 these statements were made:[5]
The main argument in favor of P ≠ NP is the total lack of fundamental progress in the area of exhaustive search. This is, in my opinion, a very weak argument. The space of algorithms is very large and we are only at the beginning of its exploration. [. . .] The resolution of Fermat's Last Theorem also shows that very simple questions may be settled only by very deep theories.
Being attached to a speculation is not a good guide to research planning. One should always try both directions of every problem. Prejudice has caused famous mathematicians to fail to solve famous problems whose solution was opposite to their expectations, even though they had developed all the methods required.
Consequences of the resolution of the problem
One of the reasons the problem attracts so much attention is the consequences of the answer. Either direction of resolution would advance theory enormously, and perhaps have huge practical consequences as well.
P = NP
A proof that P = NP could have stunning practical consequences, if the proof leads to efficient methods for solving some of the important problems in NP. It is also possible that a proof would not lead directly to efficient methods, perhaps if the proof is non-constructive, or the size of the bounding polynomial is too big to be efficient in practice. The consequences, both positive and negative, arise since various NP-complete problems are fundamental in many fields.
Cryptography, for example, relies on certain problems being difficult. A constructive and efficient solution to an NP-complete problem such as 3-SAT would break most existing cryptosystems including public-key cryptography,[15] a foundation for many modern security applications such as secure economic transactions over the Internet, and symmetric ciphers such as AES or 3DES,[16] used for the encryption of communications data. These would need to be modified or replaced by information-theoretically secure solutions.
On the other hand, there are enormous positive consequences that would follow from rendering tractable many currently mathematically intractable problems. For instance, many problems in operations research are NP-complete, such as some types of integer programming, and the travelling salesman problem, to name two of the most famous examples. Efficient solutions to these problems would have enormous implications for logistics. Many other important problems, such as some problems in protein structure prediction, are also NP-complete;[17] if these problems were efficiently solvable it could spur considerable advances in biology.
But such changes may pale in significance compared to the revolution an efficient method for solving NP-complete problems would cause in mathematics itself. According to Stephen Cook,[18]
...it would transform mathematics by allowing a computer to find a formal proof of any theorem which has a proof of a reasonable length, since formal proofs can easily be recognized in polynomial time. Example problems may well include all of the CMI prize problems.
Research mathematicians spend their careers trying to prove theorems, and some proofs have taken decades or even centuries to find after problems have been stated—for instance, Fermat's Last Theorem took over three centuries to prove. A method that is guaranteed to find proofs to theorems, should one exist of a "reasonable" size, would essentially end this struggle.
P ≠ NP
A proof that showed that P ≠ NP would lack the practical computational benefits of a proof that P = NP, but would nevertheless represent a very significant advance in computational complexity theory and provide guidance for future research. It would allow one to show in a formal way that many common problems cannot be solved efficiently, so that the attention of researchers can be focused on partial solutions or solutions to other problems. Due to widespread belief in P ≠ NP, much of this focusing of research has already taken place.[19]
Also P ≠ NP still leaves open the average-case complexity of hard problems in NP. For example, it is possible that SAT requires exponential time in the worst case, but that almost all randomly selected instances of it are efficiently solvable. Russell Impagliazzo has described five hypothetical "worlds" that could result from different possible resolutions to the average-case complexity question.[20] These range from "Algorithmica", where P = NP and problems like SAT can be solved efficiently in all instances, to "Cryptomania", where P ≠ NP and generating hard instances of problems outside P is easy, with three intermediate possibilities reflecting different possible distributions of difficulty over instances of NP-hard problems. The "world" where P ≠ NP but all problems in NP are tractable in the average case is called "Heuristica" in the paper. A Princeton University workshop in 2009 studied the status of the five worlds.[21]
Results about difficulty of proof
Although the P = NP? problem itself remains open, despite a million-dollar prize and a huge amount of dedicated research, efforts to solve the problem have led to several new techniques. In particular, some of the most fruitful research related to the P = NP problem has been in showing that existing proof techniques are not powerful enough to answer the question, thus suggesting that novel technical approaches are required.
As additional evidence for the difficulty of the problem, essentially all known proof techniques in computational complexity theory fall into one of the following classifications, each of which is known to be insufficient to prove that P ≠ NP:
| Classification | Definition |
|---|---|
| Relativizing proofs | Imagine a world where every algorithm is allowed to make queries to some fixed subroutine called an oracle, and the running time of the oracle is not counted against the running time of the algorithm. Most proofs (especially classical ones) apply uniformly in a world with oracles regardless of what the oracle does. These proofs are called relativizing. In 1975, Baker, Gill, and Solovay showed that P = NP with respect to some oracles, while P ≠ NP for other oracles.[22] Since relativizing proofs can only prove statements that are uniformly true with respect to all possible oracles, this showed that relativizing techniques cannot resolve P = NP. |
| Natural proofs | In 1993, Alexander Razborov and Steven Rudich defined a general class of proof techniques for circuit complexity lower bounds, called natural proofs. At the time all previously known circuit lower bounds were natural, and circuit complexity was considered a very promising approach for resolving P = NP. However, Razborov and Rudich showed that, if one-way functions exist, then no natural proof method can distinguish between P and NP. Although one-way functions have never been formally proven to exist, most mathematicians believe that they do, and a proof or disproof of their existence would be a much stronger statement than the quantification of P relative to NP. Thus it is unlikely that natural proofs alone can resolve P = NP. |
| Algebrizing proofs | After the Baker-Gill-Solovay result, new non-relativizing proof techniques were successfully used to prove that IP = PSPACE. However, in 2008, Scott Aaronson and Avi Wigderson showed that the main technical tool used in the IP = PSPACE proof, known as arithmetization, was also insufficient to resolve P = NP.[23] |
These barriers are another reason why NP-complete problems are useful: if a polynomial-time algorithm can be demonstrated for an NP-complete problem, this would solve the P = NP problem in a way not excluded by the above results.
These barriers have also led some computer scientists to suggest that the P versus NP problem may be independent of standard axiom systems like ZFC (cannot be proved or disproved within them). The interpretation of an independence result could be that either no polynomial-time algorithm exists for any NP-complete problem, and such a proof cannot be constructed in (e.g.) ZFC, or that polynomial-time algorithms for NP-complete problems may exist, but it's impossible to prove in ZFC that such algorithms are correct.[24] However, if it can be shown, using techniques of the sort that are currently known to be applicable, that the problem cannot be decided even with much weaker assumptions extending the Peano axioms (PA) for integer arithmetic, then there would necessarily exist nearly-polynomial-time algorithms for every problem in NP.[25] Therefore, if one believes (as most complexity theorists do) that not all problems in NP have efficient algorithms, it would follow that proofs of independence using those techniques cannot be possible. Additionally, this result implies that proving independence from PA or ZFC using currently known techniques is no easier than proving the existence of efficient algorithms for all problems in NP.
Claimed solutions
While the P versus NP problem is generally considered unsolved,[26] many amateur and some professional researchers have claimed solutions. Woeginger (2010) has a comprehensive list.[27] An August 2010 claim of proof that P ≠ NP, by Vinay Deolalikar, researcher at HP Labs, Palo Alto, received heavy Internet and press attention after being initially described as "seem[ing] to be a relatively serious attempt" by two leading specialists.[28] The proof has been reviewed publicly by academics,[29][30] and Neil Immerman, an expert in the field, had pointed out two possibly fatal errors in the proof.[31] As of September 15, 2010, Deolalikar was reported to be working on a detailed expansion of his attempted proof.[32] However, the general consensus amongst theoretical computer scientists is now that the attempted proof is neither correct nor a significant advancement in our understanding of the problem.[33]
Logical characterizations
The P = NP problem can be restated in terms of expressible certain classes of logical statements, as a result of work in descriptive complexity. All languages (of finite structures with a fixed signature including a linear order relation) in P can be expressed in first-order logic with the addition of a suitable least fixed-point combinator (effectively, this, in combination with the order, allows the definition of recursive functions); indeed, (as long as the signature contains at least one predicate or function in addition to the distinguished order relation [so that the amount of space taken to store such finite structures is actually polynomial in the number of elements in the structure]), this precisely characterizes P. Similarly, NP is the set of languages expressible in existential second-order logic—that is, second-order logic restricted to exclude universal quantification over relations, functions, and subsets. The languages in the polynomial hierarchy, PH, correspond to all of second-order logic. Thus, the question "is P a proper subset of NP" can be reformulated as "is existential second-order logic able to describe languages (of finite linearly ordered structures with nontrivial signature) that first-order logic with least fixed point cannot?". The word "existential" can even be dropped from the previous characterization, since P = NP if and only if P = PH (as the former would establish that NP = co-NP, which in turn implies that NP = PH). PSPACE = NPSPACE as established Savitch's theorem, this follows directly from the fact that the square of a polynomial function is still a polynomial function. However, it is believed, but not proven, that a similar relationship may not exist between the polynomial time complexity classes P and NP, so the question is still open.
Polynomial-time algorithms
No algorithm for any NP-complete problem is known to run in polynomial time. However, there are algorithms for NP-complete problems with the property that if P = NP, then the algorithm runs in polynomial time (although with enormous constants, making the algorithm impractical). The following algorithm, due to Levin, is such an example. It correctly accepts the NP-complete language SUBSET-SUM, and runs in polynomial time if and only if P = NP:
// Algorithm that accepts the NP-complete language SUBSET-SUM. // // This is a polynomial-time algorithm if and only if P=NP. // // "Polynomial-time" means it returns "yes" in polynomial time when // the answer should be "yes", and runs forever when it is "no". // // Input: S = a finite set of integers // Output: "yes" if any subset of S adds up to 0. // Runs forever with no output otherwise. // Note: "Program number P" is the program obtained by // writing the integer P in binary, then // considering that string of bits to be a // program. Every possible program can be // generated this way, though most do nothing // because of syntax errors.
FOR N = 1...infinity FOR P = 1...N Run program number P for N steps with input S IF the program outputs a list of distinct integers AND the integers are all in S AND the integers sum to 0
THEN OUTPUT "yes" and HALT
If, and only if, P = NP, then this is a polynomial-time algorithm accepting an NP-complete language. "Accepting" means it gives "yes" answers in polynomial time, but is allowed to run forever when the answer is "no".
This algorithm is enormously impractical, even if P = NP. If the shortest program that can solve SUBSET-SUM in polynomial time is b bits long, the above algorithm will try at least 2b−1 other programs first.
Formal definitions for P and NP
Conceptually a decision problem is a problem that takes as input some string w over an alphabet 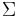 , and outputs "yes" or "no". If there is an algorithm (say a Turing machine, or a computer program with unbounded memory) that can produce the correct answer for any input string of length n in at most
, and outputs "yes" or "no". If there is an algorithm (say a Turing machine, or a computer program with unbounded memory) that can produce the correct answer for any input string of length n in at most 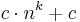 steps, where k and c are constants independent of the input string, then we say that the problem can be solved in polynomial time and we place it in the class P. Formally, P is defined as the set of all languages that can be decided by a deterministic polynomial-time Turing machine. That is,
steps, where k and c are constants independent of the input string, then we say that the problem can be solved in polynomial time and we place it in the class P. Formally, P is defined as the set of all languages that can be decided by a deterministic polynomial-time Turing machine. That is,
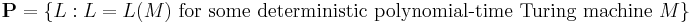
where
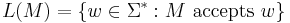
and a deterministic polynomial-time Turing machine is a deterministic Turing machine M that satisfies the following two conditions:
- M halts on all input w and
- there exists
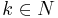 such that
such that 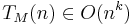 (where O refers to the big O notation),
(where O refers to the big O notation),
-
- where
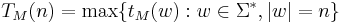
- and
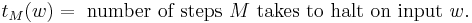
- where
NP can be defined similarly using nondeterministic Turing machines (the traditional way). However, a modern approach to define NP is to use the concept of certificate and verifier. Formally, NP is defined as the set of languages over a finite alphabet that have a verifier that runs in polynomial time, where the notion of "verifier" is defined as follows.
Let L be a language over a finite alphabet, .
L ∈ NP if, and only if, there exists a binary relation 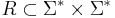 and a positive integer k such that the following two conditions are satisfied:
and a positive integer k such that the following two conditions are satisfied:
- For all
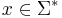 ,
, 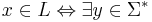 such that
such that 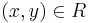 and
and 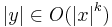 ; and
; and - the language
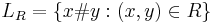 over
over 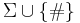 is decidable by a Turing machine in polynomial time.
is decidable by a Turing machine in polynomial time.
A Turing machine that decides LR is called a verifier for L and a y such that 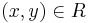 is called a certificate of membership of x in L.
is called a certificate of membership of x in L.
In general, a verifier does not have to be polynomial-time. However, for L to be in NP, there must be a verifier that runs in polynomial time.
Example
Let
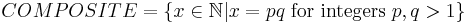
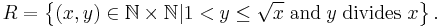
Clearly, the question of whether a given x is a composite is equivalent to the question of whether x is a member of COMPOSITE. It can be shown that COMPOSITE ∈ NP by verifying that it satisfies the above definition (if we identify natural numbers with their binary representations).
COMPOSITE also happens to be in P.[34][35]
Formal definition for NP-completeness
There are many equivalent ways of describing NP-completeness.
Let 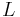 be a language over a finite alphabet
be a language over a finite alphabet 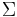 .
.
is NP-complete if, and only if, the following two conditions are satisfied:
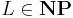 ; and
; and- any
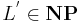 is polynomial-time-reducible to (written as
is polynomial-time-reducible to (written as 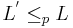 ), where if, and only if, the following two conditions are satisfied:
), where if, and only if, the following two conditions are satisfied:
- There exists
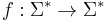 such that
such that 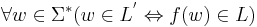 ; and
; and - there exists a polynomial-time Turing machine that halts with
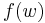 on its tape on any input
on its tape on any input 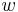 .
.
- There exists
See also
Notes
- ^ a b R. E. Ladner "On the structure of polynomial time reducibility," Journal of the ACM, 22, pp. 151–171, 1975. Corollary 1.1. ACM site.
- ^ Cook, Stephen (1971). "The complexity of theorem proving procedures". Proceedings of the Third Annual ACM Symposium on Theory of Computing. pp. 151–158. http://portal.acm.org/citation.cfm?coll=GUIDE&dl=GUIDE&id=805047.
- ^ Lance Fortnow, The status of the P versus NP problem, Communications of the ACM 52 (2009), no. 9, pp. 78–86. doi:10.1145/1562164.1562186
- ^ Sipser, Michael: Introduction to the Theory of Computation, Second Edition, International Edition, page 270. Thomson Course Technology, 2006. Definition 7.19 and Theorem 7.20.
- ^ a b c William I. Gasarch (June 2002). "The P=?NP poll." (PDF). SIGACT News 33 (2): 34–47. doi:10.1145/1052796.1052804. http://www.cs.umd.edu/~gasarch/papers/poll.pdf. Retrieved 2008-12-29.
- ^ Scott Aaronson. "PHYS771 Lecture 6: P, NP, and Friends". http://www.scottaaronson.com/democritus/lec6.html. Retrieved 2007-08-27.
- ^ Aviezri Fraenkel and D. Lichtenstein (1981). "Computing a perfect strategy for n×n chess requires time exponential in n". J. Comb. Th. A (31): 199–214.
- ^ David Eppstein. "Computational Complexity of Games and Puzzles". http://www.ics.uci.edu/~eppstein/cgt/hard.html.
- ^ Arvind, Vikraman; Kurur, Piyush P. (2006). "Graph isomorphism is in SPP". Information and Computation 204 (5): 835–852. doi:10.1016/j.ic.2006.02.002.
- ^ Uwe Schöning, "Graph isomorphism is in the low hierarchy", Proceedings of the 4th Annual Symposium on Theoretical Aspects of Computer Science, 1987, 114–124; also: Journal of Computer and System Sciences, vol. 37 (1988), 312–323
- ^ Lance Fortnow. Computational Complexity Blog: Complexity Class of the Week: Factoring. September 13, 2002. http://weblog.fortnow.com/2002/09/complexity-class-of-week-factoring.html
- ^ Pisinger, D. 2003. "Where are the hard knapsack problems?" Technical Report 2003/08, Department of Computer Science, University of Copenhagen, Copenhagen, Denmark
- ^ Gondzio, Jacek; Terlaky, Tamás (1996). "3 A computational view of interior point methods". In J. E. Beasley. Advances in linear and integer programming. Oxford Lecture Series in Mathematics and its Applications. 4. New York: Oxford University Press. pp. 103–144. MR1438311. Postscript file at website of Gondzio and at McMaster University website of Terlaky. http://www.maths.ed.ac.uk/~gondzio/CV/oxford.ps.
- ^ Scott Aaronson. "Reasons to believe". http://scottaaronson.com/blog/?p=122., point 9.
- ^ See Horie, S. and Watanabe, O. (1997). "Hard instance generation for SAT". Algorithms and Computation (Springer): 22–31. arXiv:cs/9809117. for a reduction of factoring to SAT. A 512 bit factoring problem (8400 MIPS-years when factored) translates to a SAT problem of 63,652 variables and 406,860 clauses.
- ^ See, for example, Massacci, F. and Marraro, L. (2000). "Logical cryptanalysis as a SAT problem". Journal of Automated Reasoning (Springer) 24 (1): 165–203. doi:10.1023/A:1006326723002. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.104.962&rep=rep1&type=pdf. in which an instance of DES is encoded as a SAT problem with 10336 variables and 61935 clauses. A 3DES problem instance would be about 3 times this size.
- ^ Berger B, Leighton T (1998). "Protein folding in the hydrophobic-hydrophilic (HP) model is NP-complete". J. Comput. Biol. 5 (1): 27–40. doi:10.1089/cmb.1998.5.27. PMID 9541869.
- ^ Cook, Stephen (April 2000). The P versus NP Problem. Clay Mathematics Institute. http://www.claymath.org/millennium/P_vs_NP/Official_Problem_Description.pdf. Retrieved 2006-10-18.
- ^ L. R. Foulds (October 1983). "The Heuristic Problem-Solving Approach". The Journal of the Operational Research Society 34 (10): 927–934. doi:10.2307/2580891. JSTOR 2580891.
- ^ R. Impagliazzo, "A personal view of average-case complexity," sct, pp.134, 10th Annual Structure in Complexity Theory Conference (SCT'95), 1995
- ^ http://intractability.princeton.edu/blog/2009/05/program-for-workshop-on-impagliazzos-worlds/
- ^ T. P. Baker, J. Gill, R. Solovay. Relativizations of the P =? NP Question. SIAM Journal on Computing, 4(4): 431–442 (1975)
- ^ S. Aaronson and A. Wigderson (2008). "Algebrization: A New Barrier in Complexity Theory". Proceedings of ACM STOC'2008. pp. 731–740. doi:10.1145/1374376.1374481. http://www.scottaaronson.com/papers/alg.pdf.
- ^ Aaronson, Scott. "Is P Versus NP Formally Independent?". http://www.scottaaronson.com/papers/pnp.pdf.
- ^ Ben-David, Shai; Halevi, Shai (1992). On the independence of P versus NP. Technical Report. 714. Technion. http://www.cs.technion.ac.il/~shai/ph.ps.gz.
- ^ John Markoff (8 October 2009). "Prizes Aside, the P-NP Puzzler Has Consequences". The New York Times. http://www.nytimes.com/2009/10/08/science/Wpolynom.html.
- ^ Gerhard J. Woeginger (2010-08-09). "The P-versus-NP page". http://www.win.tue.nl/~gwoegi/P-versus-NP.htm. Retrieved 2010-08-12.
- ^ Markoff, John (16 August 2010). "Step 1: Post Elusive Proof. Step 2: Watch Fireworks.". The New York Times. http://www.nytimes.com/2010/08/17/science/17proof.html?_r=1. Retrieved 20 September 2010.
- ^ Polymath project wiki. "Deolalikar's P vs NP paper". http://michaelnielsen.org/polymath1/index.php?title=Deolalikar_P_vs_NP_paper.
- ^ Science News, "Crowdsourcing peer review"
- ^ Dick Lipton (12 August 2010). "Fatal Flaws in Deolalikar's Proof?". http://rjlipton.wordpress.com/2010/08/12/fatal-flaws-in-deolalikars-proof/.
- ^ Dick Lipton (15 September 2010). "An Update on Vinay Deolalikar's Proof". http://rjlipton.wordpress.com/2010/09/15/an-update-on-vinay-deolalikars-proof/. Retrieved December 31, 2010.
- ^ Gödel’s Lost Letter and P=NP, Update on Deolalikar’s Proof that P≠NP
- ^ M. Agrawal, N. Kayal, N. Saxena. "Primes is in P" (PDF). http://www.cse.iitk.ac.in/users/manindra/algebra/primality_v6.pdf. Retrieved 2008-12-29.
- ^ AKS primality test
Further reading
- Fraenkel, A. S.; Lichtenstein, D.. Computing a Perfect Strategy for n*n Chess Requires Time Exponential in N.. doi:10.1007/3-540-10843-2+23. http://www.pubzone.org/dblp/conf/icalp/FraenkelL81.
- Garey, Michael (1979). Computers and Intractability. San Francisco: W.H. Freeman. ISBN 0716710455.
- Goldreich, Oded (2010). P, Np, and Np-Completeness. Cambridge: Cambridge University Press. ISBN 9780521122542.
- Immerman, N. (1983). Languages which capture complexity classes. pp. 347. doi:10.1145/800061.808765.
- Cormen, Thomas (2001). Introduction to Algorithms. Cambridge: MIT Press. ISBN 0262032937.
- Papadimitriou, Christos (1994). Computational Complexity. Boston: Addison-Wesley. ISBN 0201530821.
- Fortnow, L. (2009). "The status of the P versus NP problem". Communications of the ACM 52 (9): 78. doi:10.1145/1562164.1562186.
External links
- The Clay Mathematics Institute Millennium Prize Problems
- The Clay Math Institute Official Problem DescriptionPDF (118 KB)
- Ian Stewart on Minesweeper as NP-complete at The Clay Math Institute
- Gerhard J. Woeginger. The P-versus-NP page. A list of links to a number of purported solutions to the problem. Some of these links state that P equals NP, some of them state the opposite. It is probable that all these alleged solutions are incorrect.
- Computational Complexity of Games and Puzzles
- Complexity Zoo: Class P, Complexity Zoo: Class NP
- Scott Aaronson 's Shtetl Optimized blog: Reasons to believe, a list of justifications for the belief that P ≠ NP
|
|||||||||||||||||